Research
We are pursuing several research directions simultaneously in the lab. The following vignettes provide a snapshot of some of the key challenges we are addressing and the innovative solutions we are developing.
Real-time, in situ Robot Learning
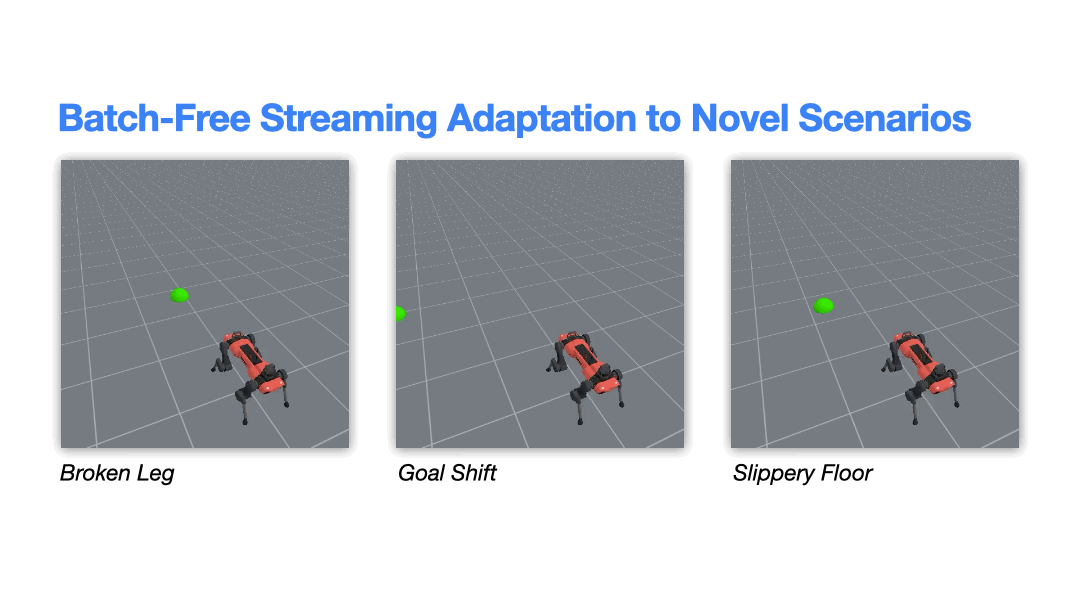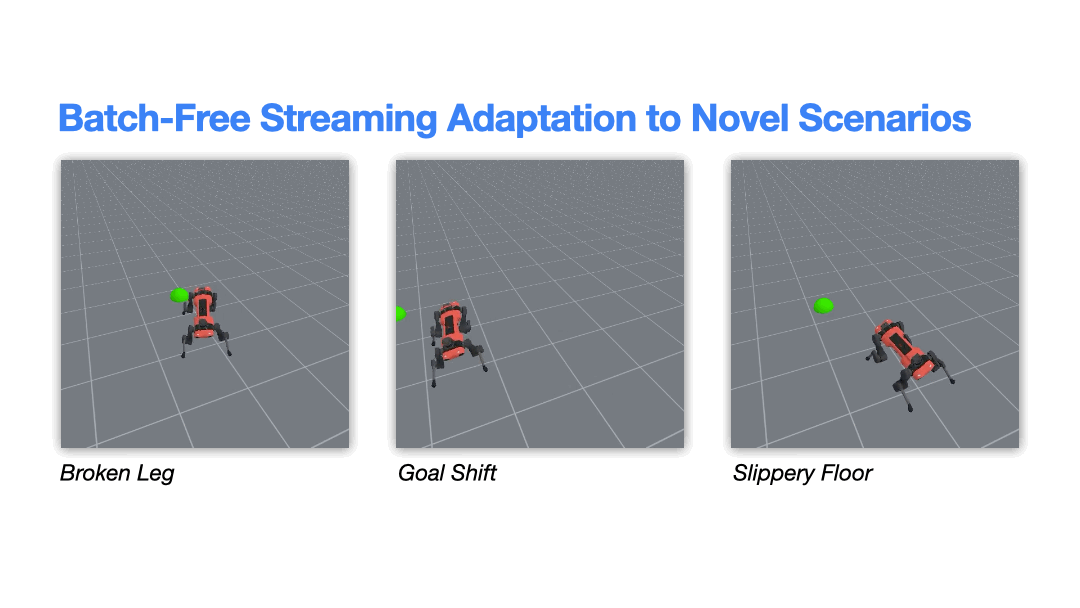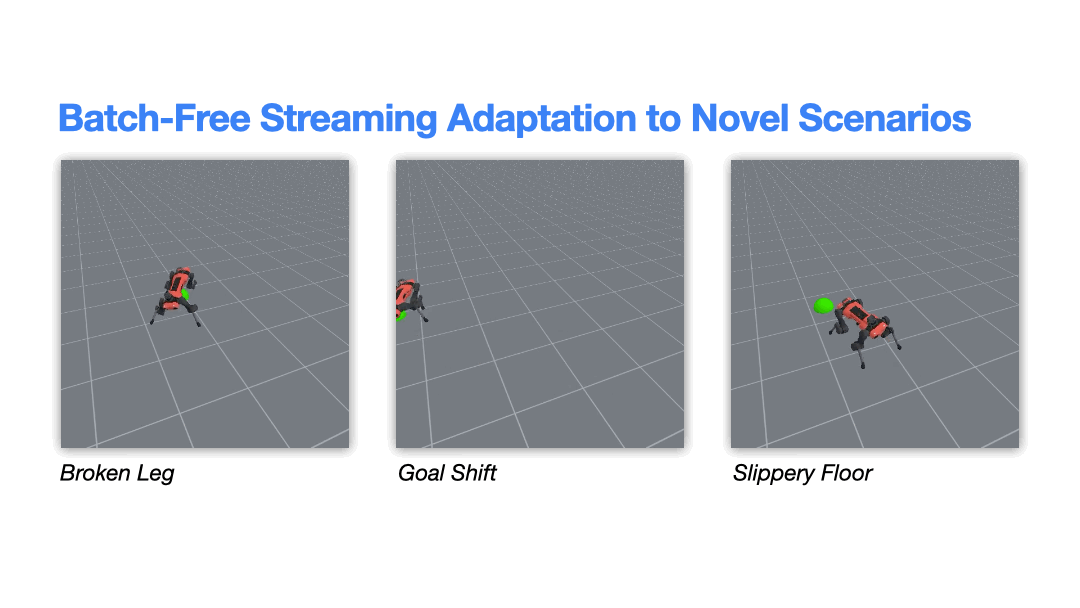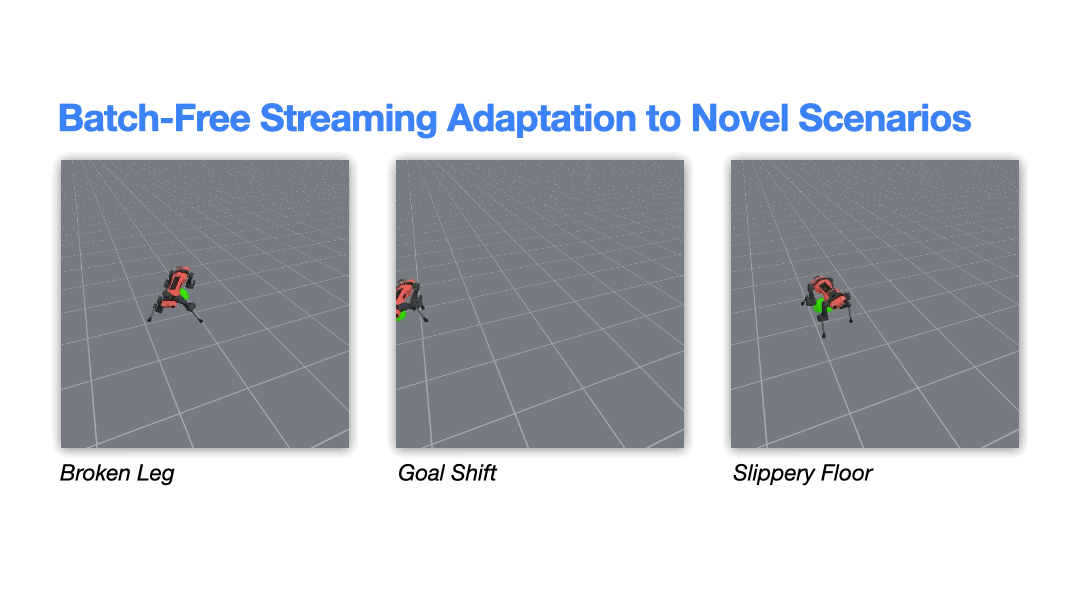
A growing focus of our research is enabling robots to learn and adapt in real time, directly from their ongoing experience, rather than relying solely on offline, batch-based training. While most modern robotic learning pipelines depend on large pre-collected datasets and retraining cycles, we instead explore algorithms that update continuously, allowing robots to refine their behavior in situ as conditions change.
Building on ideas from streaming reinforcement learning and interactive learning, we investigate methods that can adapt from a live stream of data, without replay buffers or expensive retraining phases, enabling rapid responses to shifts in the robot, environment, or task . We also study approaches that combine offline pretraining with efficient online updates, allowing large models to be incrementally refined through interaction while maintaining computational efficiency .
Automatic Mesh Generation for Robotics
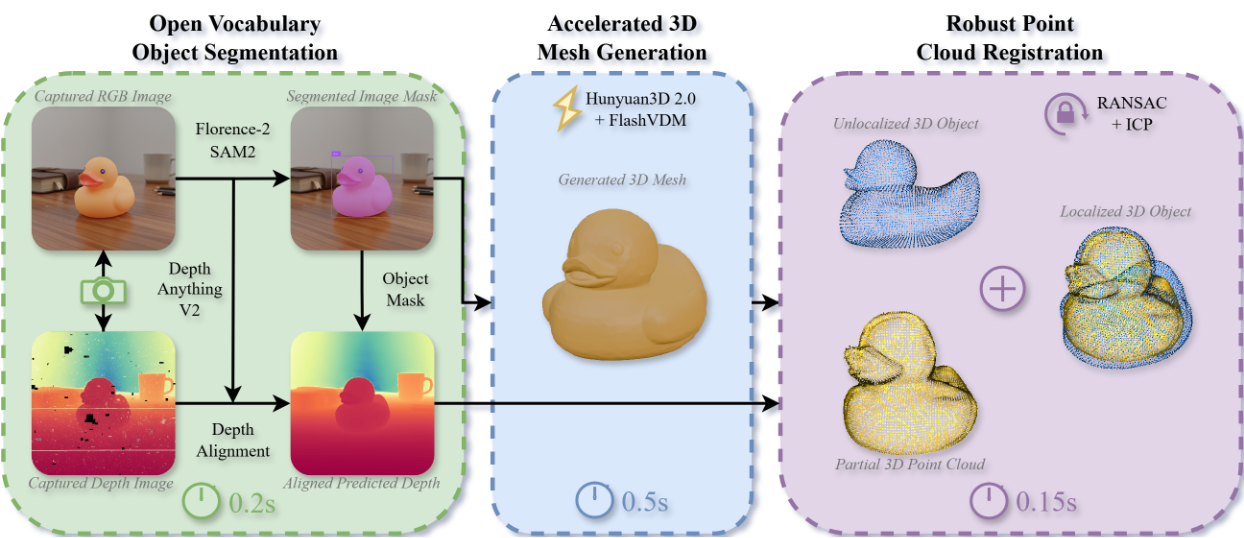
A growing direction in our lab is the development of methods for automatic 3D mesh generation that make rich geometric models available to robots on demand. Rather than assuming that objects already have high-quality CAD models, we study how robots can generate useful 3D geometry directly from visual observations, enabling faster deployment in open-world environments and reducing the need for manual asset creation.
Our work focuses especially on making generated geometry practical for robotics, not just visually plausible. This includes systems that can produce contextually grounded meshes in under a second from RGB-D input by combining fast segmentation, accelerated generative modeling, and geometric registration, so that the resulting object models are immediately aligned with the scene and ready for downstream manipulation and planning . We also investigate methods for improving the speed, quality, and editability of autoregressive mesh generation through retrieval-augmented approaches that support parallel generation and localized editing without retraining .
Beyond raw mesh generation, we are interested in producing geometry that is directly usable for physics and motion planning. To this end, we explore simulation-ready representations such as direct image-to-convex decomposition, allowing robots to obtain compact, watertight collision models that are well suited for contact reasoning, obstacle avoidance, and fast optimization-based planning . Together, this research aims to turn automatic geometry generation into a practical perception tool for real-world robotic systems.
Computational Differentiation and Vector Recovery
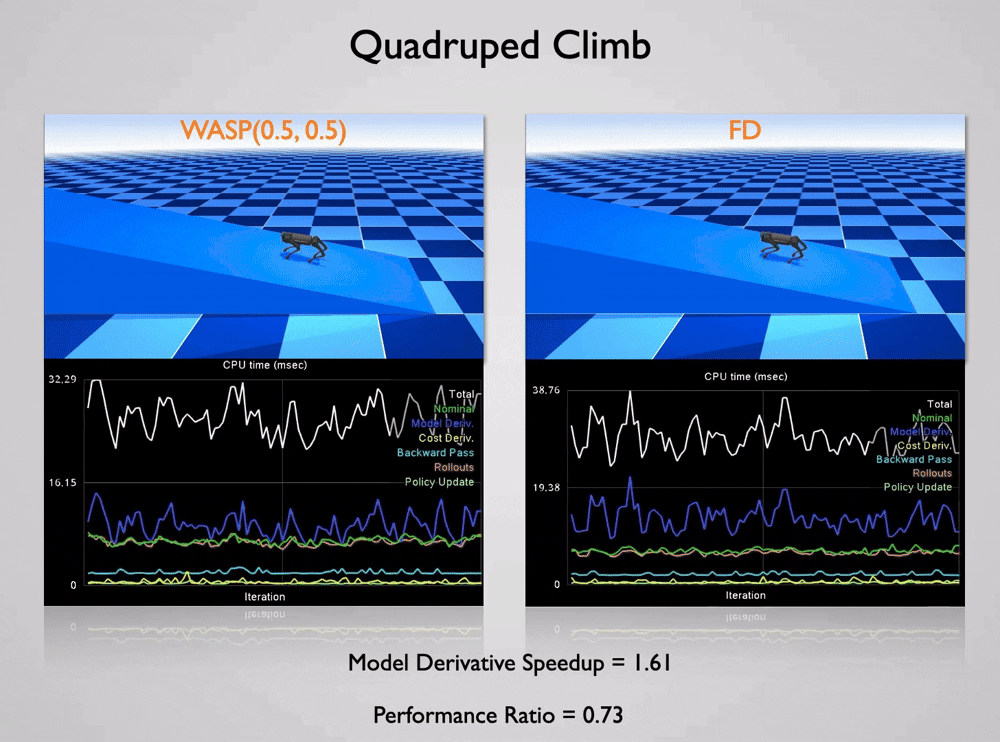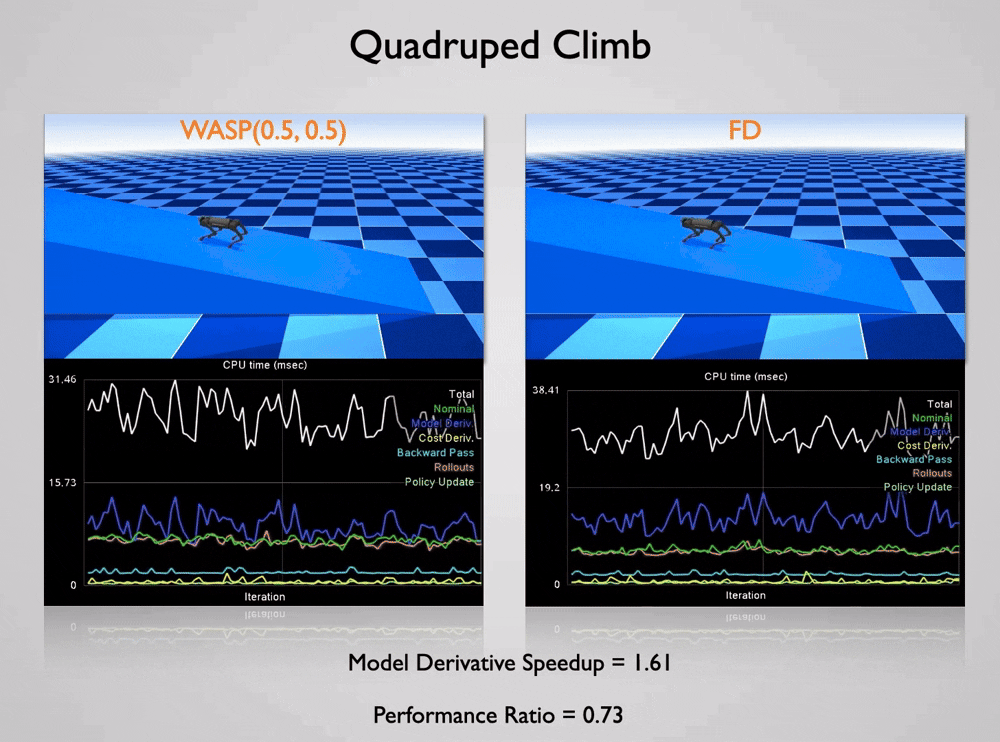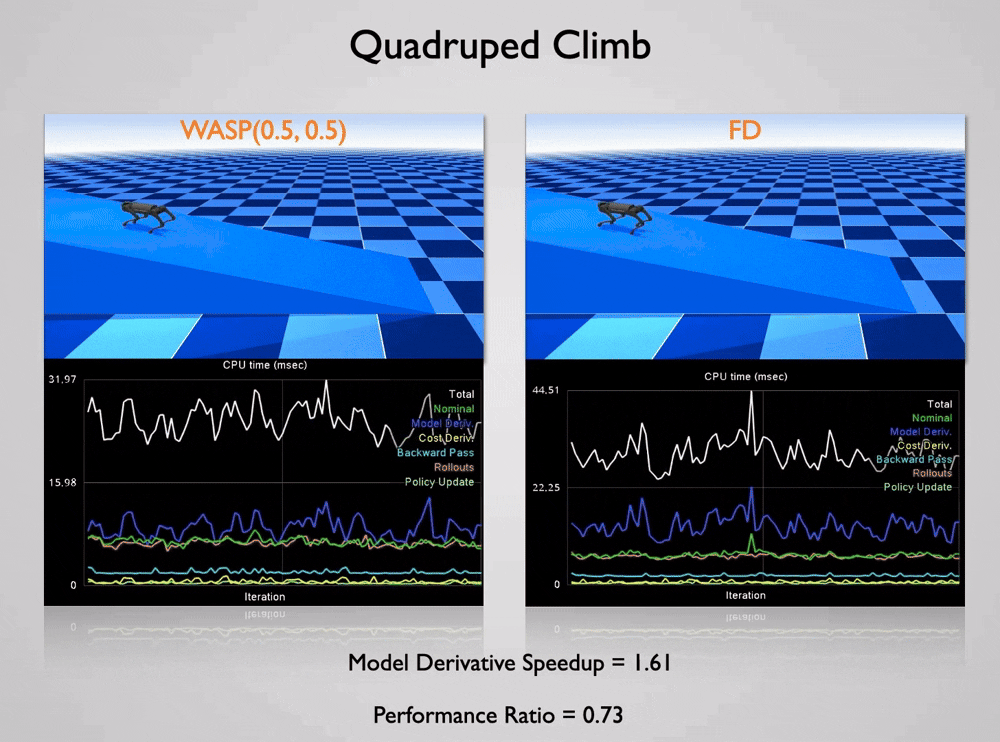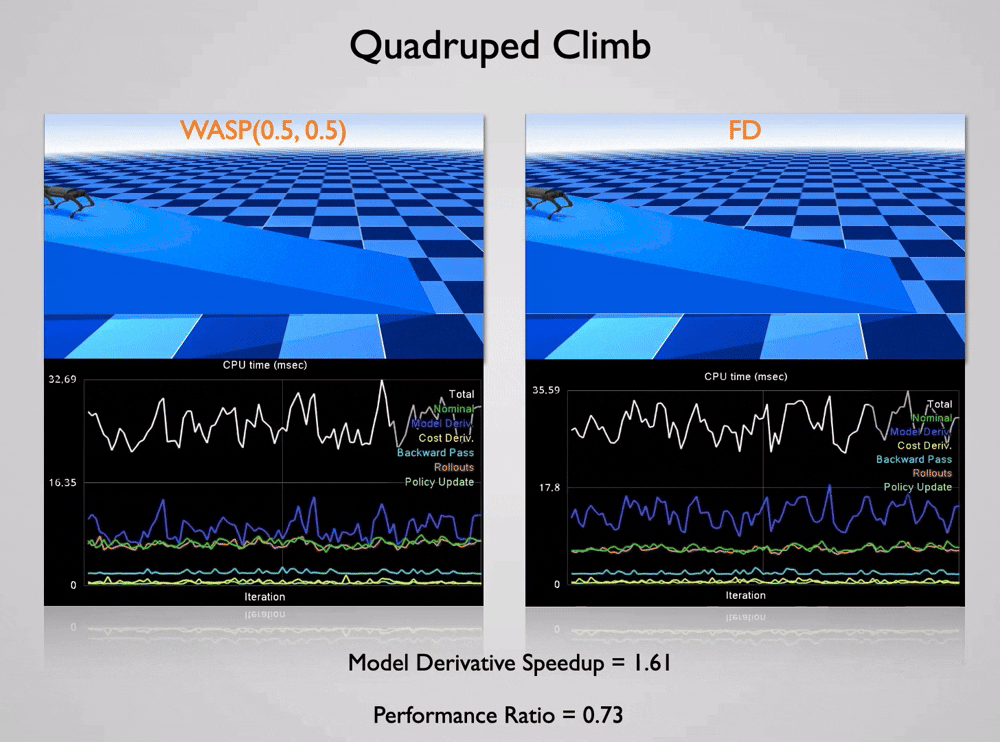
We study new approaches to computing derivatives efficiently in settings where traditional methods, such as exact automatic differentiation or naive finite differencing, are too slow, memory-intensive, or unstable. Because derivatives are a fundamental building block across optimization, learning, simulation, and control, improving how they are computed has broad implications across scientific computing and engineering.
A central idea in our work is to exploit structure and coherence in sequences of derivative computations. In many applications, derivatives are not computed in isolation, but rather repeatedly along closely related inputs, such as during iterative optimization or simulation. By reusing information from prior evaluations, methods like Web of Affine Spaces (WASP) can construct accurate derivative approximations with only a small number of new function queries, significantly improving efficiency while maintaining stability . These ideas are particularly impactful in real-time systems, where derivatives must be recomputed continuously to support fast decision-making and control .
We also explore practical systems for lightweight automatic differentiation, enabling efficient derivative computation across modern programming environments and deployment settings, including resource-constrained or performance-critical applications .
Looking ahead, we are beginning to connect these ideas to the emerging perspective of vector recovery. Many derivative computations, especially those based on perturbations, can be interpreted as measuring directional derivatives, which correspond to dot products with an underlying gradient. From this viewpoint, differentiation becomes a structured recovery problem: reconstructing a vector from a set of directional measurements. This connection suggests new algorithmic directions that may enable more efficient, scalable, and noise-robust methods for computing gradients in high-dimensional systems.
Efficient Optimizers for Neural Networks
We explore new approaches to optimization for neural networks that prioritize efficiency, stability, and scalability, particularly in regimes where standard gradient-based methods are limited by memory, compute, or noise. While modern optimizers rely heavily on backpropagation and first-order updates, many emerging applications—such as edge deployment, large-scale models, and black-box settings—require more flexible and lightweight alternatives.
One direction we investigate is structure-aware and derivative-free optimization, where gradients are approximated using minimal function evaluations while still maintaining stable descent. For example, coherence-based methods such as Coherent Coordinate Descent (CoCD) leverage temporal structure in optimization trajectories to reuse past gradient information, achieving strong sample efficiency and robustness without relying on full gradient computation . These approaches highlight how incorporating structure—rather than randomness alone—can significantly improve convergence behavior.
Looking forward, we are particularly interested in developing optimizers that better capture second-order and curvature information while remaining computationally efficient. By designing methods that approximate or implicitly exploit curvature, without the full cost of classical second-order techniques, we aim to achieve faster convergence, improved stability in non-convex landscapes, and more reliable training across a wide range of neural architectures.
Spatial Computing for Embodied Intelligence
We investigate spatial computing as a foundational paradigm for improving the efficiency, robustness, and generalization of embodied intelligent systems. Rather than treating space as an implicit structure that neural networks must rediscover from data, this strategy explicitly encodes geometry using mathematical frameworks such as Lie groups, Lie algebras, and geometric algebra.
A key motivation comes from modern robot learning pipelines, where policies often operate on raw sensory inputs (e.g., images) and must internally reconstruct notions of position, orientation, and motion. As shown in recent work, replacing high-dimensional observations with structured spatial representations (e.g., SE(3) poses) leads to dramatically more compact and efficient learning. For instance, diffusion policies conditioned on object poses instead of images achieve comparable or better performance with far fewer parameters and improved training efficiency . This highlights the broader principle that well-chosen geometric representations reduce both sample complexity and model size.
Building on this, we are particularly interested in embedding geometric inductive biases directly into learning systems. One promising direction is the use of Projective Geometric Algebra (PGA), which provides a unified representation of spatial primitives and transformations (e.g., rotations, translations, and rigid motions) through multivectors. By incorporating these representations into neural architectures, models no longer need to relearn basic spatial relationships for each task. As demonstrated in recent hybrid diffusion policy architectures, introducing PGA-based encoders and decoders enables faster convergence and improved task performance by allowing networks to reason about geometry more naturally and efficiently .
More broadly, spatial computing suggests a shift in how we design intelligent systems:
- Lie groups and Lie algebras provide minimal, well-behaved representations of continuous transformations (e.g., SE(3), SO(3)), enabling stable control and optimization.
- Geometric algebra unifies these representations into a single computational framework, supporting expressive yet compact reasoning about space.
- Structured state representations (poses, transforms, constraints) replace unstructured inputs, reducing the burden on learning systems.
Looking forward, we aim to further unify these ideas into geometry-native learning and control pipelines, where perception, planning, and optimization all operate within consistent spatial representations. This includes developing architectures that are equivariant to geometric transformations, integrating curvature-aware optimization directly in Lie spaces, and designing policies that reason over spatial structure rather than raw data. The long-term goal is to move from systems that approximate geometry to systems that compute with geometry natively, yielding faster, more reliable, and more interpretable robotic behavior.
LLMs and VLMs for Robot Planning
We study how large language models (LLMs) and vision-language models (VLMs) can make robot planning more flexible, interpretable, and adaptable in open-ended environments. Rather than treating these models as end-to-end controllers, our work explores how they can serve as high-level reasoning engines that translate human intent into structured plans the robot can execute reliably.
A central theme in this research is using language and vision models to produce explicit, grounded planning representations instead of opaque action outputs. For manipulation, this includes converting free-form instructions into sequences of atomic, interpretable skill elements whose continuous parameters are grounded in the current scene, making plans easier to inspect, modify, and reuse. At the task level, we investigate how LLMs can support sequential action selection, choosing the next best action based on current obstacles, failed attempts, and blocking conditions, rather than relying only on fixed action scripts or exhaustive search.
We are also interested in pushing planning toward settings with minimal task-specific engineering. This includes frameworks in which an LLM decomposes instructions, generates executable behavior structures, and refines them online when execution errors occur. Together, this work aims to leverage LLMs and VLMs not just for generating plausible plans, but for enabling robot planning systems that are grounded, transparent, and robust to changing real-world conditions.
Selected publications
AI for Robotic Surgery
We explore how artificial intelligence can enhance robotic surgery by extracting actionable insights from intraoperative data and enabling more precise, data-driven decision-making. With the rapid growth of minimally invasive and robotic-assisted procedures, surgical video has become a rich but underutilized source of information about technique, performance, and outcomes. Our work focuses on transforming these raw data streams into quantitative, interpretable metrics that can support both surgeons and learning systems.
A central example of this effort is our work on analyzing critical exposure during division of the inferior mesenteric artery (IMA) in colorectal surgery. Using intraoperative robotic surgery videos, we develop deep learning and 3D geometric modeling methods to quantify key aspects of surgical technique, including instrument angles, tissue geometry, and exposure quality. These models can recover spatial relationships—such as the alignment between the stapler and the IMA, as well as surface area and visibility of critical anatomy—and identify consistent patterns across surgeons, even in highly variable operative environments.
More broadly, this line of research aims to establish a foundation for data-driven surgical understanding, where complex procedures can be decomposed into measurable, reproducible components. By automating the analysis of surgical maneuvers, these systems have the potential to support real-time feedback, surgical training, retrospective review, and credentialing, while also informing best practices and improving patient outcomes.
In collaboration with clinicians and researchers at the Yale School of Medicine, we are expanding these approaches toward real-time, in-the-loop surgical intelligence, where AI systems not only analyze procedures offline but also assist during surgery by providing guidance, monitoring safety-critical steps, and adapting to the evolving surgical scene.
Motion Generation Algorithms
A core focus of our research in the APOLLO Lab is enabling robots to operate effectively in the fast-changing, complex environments of the real world. Central to this effort is the development of real-time, high-speed optimization and planning algorithms that allow robots to make decisions and adjust their actions on the fly.
We explore new approaches in planning, optimization, sensing, and learning that prioritize both computational efficiency and responsiveness, enabling robots to continuously replan and control their movements under tight time constraints. These methods allow robots to react quickly to uncertainty, dynamic obstacles, and human interaction while maintaining stability and precision.
By designing algorithms and frameworks for rapid decision-making and control, we aim to expand a robot’s ability to autonomously perform tasks with robustness and flexibility, whether manipulating objects, navigating cluttered spaces, or collaborating with humans.
Combining Visual + Manipulation Learning
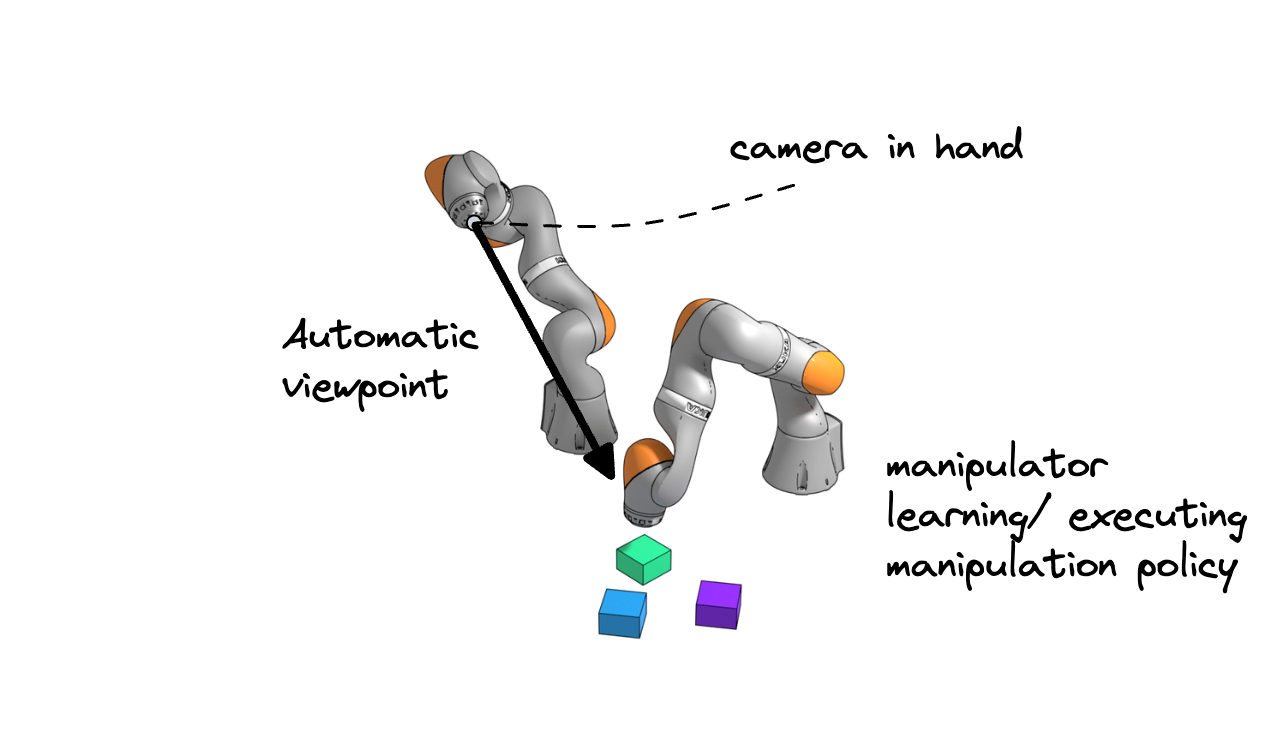
One of our central goals is to develop adaptive robotic systems that tightly couple manipulation and perception. In particular, we design robots that learn how to act and where to look at the same time, mirroring how humans coordinate movement with visual attention.
Rather than relying on fixed, static cameras, these systems actively adjust their viewpoints to gather the most informative visual data, reducing challenges such as occlusions and partial observability. By jointly learning manipulation strategies and viewpoint selection, the robot aligns its actions with its perception in a unified, closed-loop process.
This integrated approach leads to faster learning, more efficient behavior, and greater robustness in dynamic, real-world environments. Whether deployed across teams of robots or embodied in a single humanoid system, tightly coupling perception and action enables more capable, flexible, and intelligent robotic behavior.
Selected publications
- Optimizing Active Perception for Learning Simultaneous Viewpoint Selection and Manipulation with Diffusion Policy
- PRISM-DP: Spatial Pose-based Observations for Diffusion-Policies via Segmentation, Mesh Generation, and Pose Tracking
- Hybrid Diffusion Policies with Projective Geometric Algebra for Efficient Robot Manipulation Learning
Software Tools for Robotics Research
We develop software tools that streamline and standardize robotics research workflows, with a focus on reducing redundancy, improving interoperability, and accelerating development across simulation, planning, and visualization. Many robotics pipelines today rely on fragmented tooling, where core information, such as kinematics, geometry, and collision structure, is repeatedly recomputed across different systems. Our work aims to replace this pattern with shared, extensible representations and practical tooling.
A central contribution is the Universal Robot Description Directory (URDD), a modular representation that organizes rich, derived robot information into structured, reusable components. Unlike traditional formats that store only minimal data, URDD precomputes and standardizes key quantities, such as kinematic chains, degrees of freedom mappings, and geometric approximations, so they can be directly used across applications without repeated processing . This reduces boilerplate code and enables more consistent behavior across planning, control, and simulation systems.
We also build interactive tools for geometric reasoning and collision analysis, including systems for generating and visualizing self-collision matrices. These tools combine automatic preprocessing with real-time visualization, allowing users to explore robot configurations, inspect proximity relationships, and refine collision models through intuitive interfaces. By supporting multiple geometric representations and exporting results in standard formats, they improve both the efficiency and reliability of downstream algorithms .
Finally, we develop tools for high-quality visualization and communication, such as lightweight libraries that integrate robotics workflows directly into platforms like Blender. These systems allow researchers to rapidly generate publication-ready figures, animations, and explanatory diagrams from standard robot descriptions, lowering the barrier to clear and compelling visual communication .
Together, this line of work focuses on building practical, reusable infrastructure that supports the full lifecycle of robotics research, from modeling and computation to visualization and dissemination, enabling faster iteration and more robust system development.